Deep Learning NLP
1. CNN如何应用在NLP上
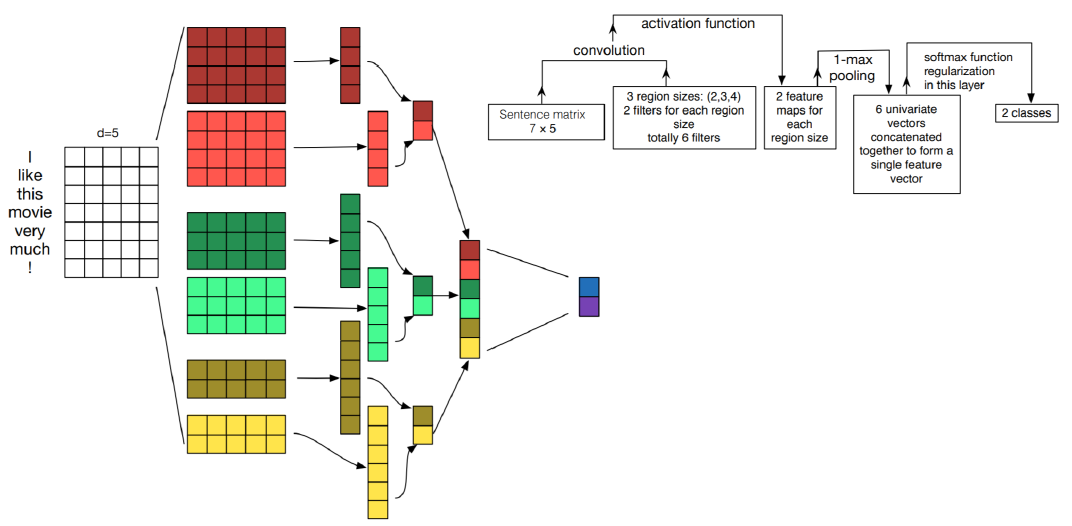
下图是一个很好的例子:
- 词要用向量的形式表达,假设词向量的大小为$d$。卷积核的列向量维度必须等于$d$,小于$d$的话这个词就表达不完整,就没意义了。$d$是一个词的最小语束。
- 卷积核的大小为$r \times d$,其中$r$为自定义变量,表示考虑相邻多少个词之间的联系。$r$为1是个unigram model;$r$为2是个bigram model;$r$为3是个trigram model。下图模型可以看成是个混合模型。所以说,CNN一样可以体现出语言是时序特征,不过只能挖掘相邻词之间的关系。
- 这是我自己以前可能忽略的一个问题,feature map里面值比较大的元素可以理解为比较重要,对结果的贡献比较大。这就是max pooling背后的逻辑。但是我觉得哈,同等kernel大小来说,这还是比较公平的,但是就下面这个混合模型来说,大kernel对比于小kernel来说应该会更容易取得大值吧。
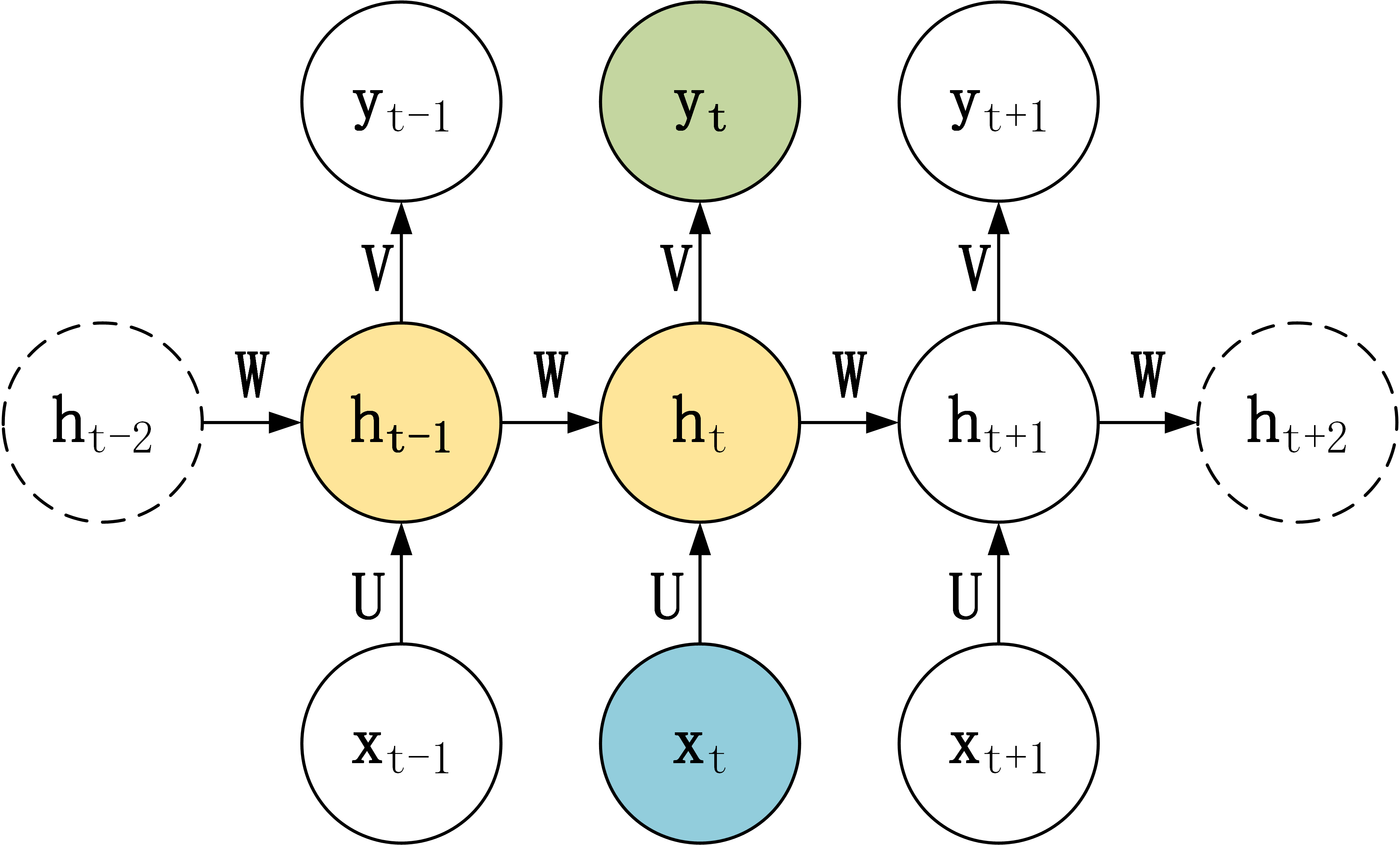
2. RNN
这里先放一个最典型的RNN结构图,主要是为了follow图中的参数notation,为了解释接下来的内容做铺垫。
2.1. Seq2Seq
Encoder-Decoder其实是一个general的框架,由编码器(Encoder),中间向量(State Vector),和解码器(Decoder)三部分组成。根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM (单向or双向都可以)或者 GRU )。Encoder-Decoder的应用范围很广,机器翻译(文字-文字),语音识别(语音-文字),图像描述生成(图片-文字)。Auto-encoder是这个框架的其中的一种特例,输入和输出一样,目的是找到数据的最好的压缩方式。
Seq2Seq其实还是Encoder-Decoder的思想。Seq2Seq可以处理变长的输入和输出,但是其实这也没啥神奇的地方,底层实现还是要定义足够长的定长的输入向量和输出向量结构,然后通过序列起始和结束标识符+补全字符的方式来实现变长处理。下面是三种常见的Seq2Seq的模型结构。这三种 Seq2Seq 模型的主要区别在于 Decoder,他们的 Encoder 都是一样的。Encoder 的LSTM 接受输入$X$,最终输出一个编码所有信息的上下文向量 $c$。其中上下文向量 $c$有多种计算方式:
-
可以直接使用最后一个神经元的隐藏状态 $h_N$ 表示: \(c=h_{N}\)
-
也可以在最后一个神经元的隐藏状态上进行某种变换 $h_N$ 而得到,$q$ 函数表示某种变换: \(c=q(h_{N})\)
-
也可以使用所有神经元的隐藏状态 $h_1$,$h_2$,…,$h_N$计算得到: \(c=q(h_1,h_2,...,h_N)\)
得到上下文向量 $c$ 之后,需要传递到 Decoder。
第一种:
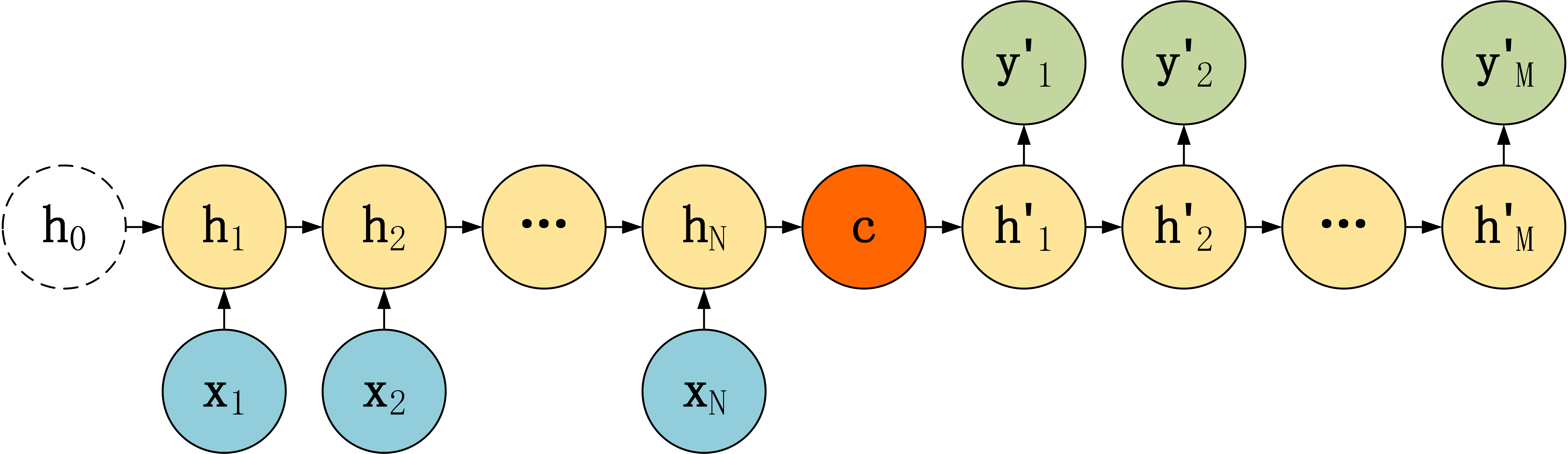
第一种Decoder比较简单,将上下文向量 $c$当成是LSTM的初始隐藏状态,输入到LSTM中,后续只接受上一个神经元的隐藏层状态 $h’$ 而不接收其他的输入$X$。这种Decoder 结构的隐藏层及输出的计算公式: \(\begin{aligned} h_{1}^{\prime} &=\sigma(W c+b_{hidden}) \\ h_{t}^{\prime}=& \sigma\left(W h_{t-1}^{\prime}+b_{hidden}\right) \\ y_{t}^{\prime} &=\sigma\left(V h_{t}^{\prime}+b_{output}\right) \end{aligned}\)
第二种:
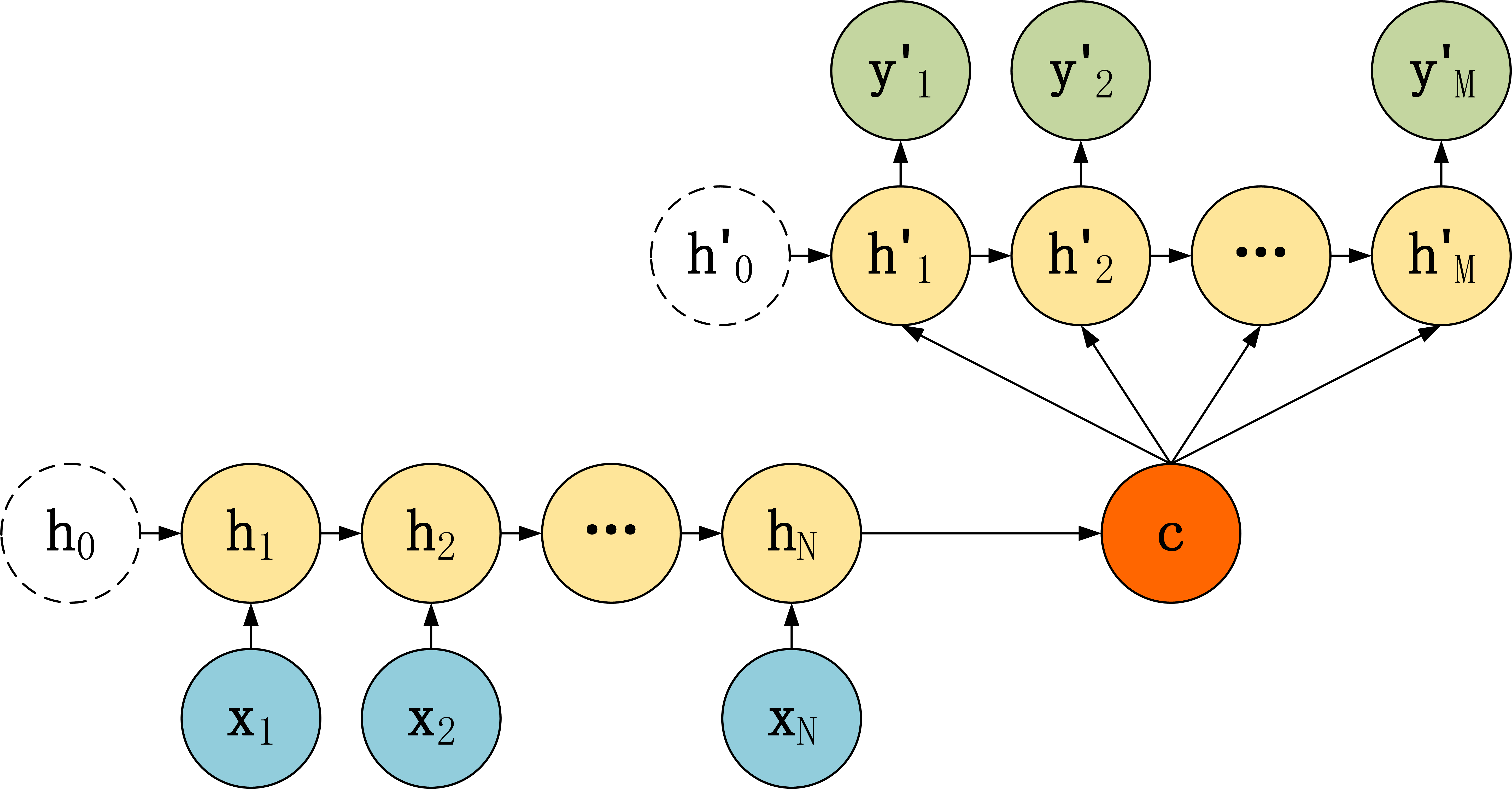
第二种 Decoder 结构有了自己的初始隐藏层状态 $h’_0$,不再把上下文向量 $c$ 当成是LSTM的初始隐藏状态,而是当成LSTM每一个神经元的输入。可以看到在 Decoder 的每一个神经元都拥有相同的输入 $c$,这种 Decoder 的隐藏层及输出计算公式: \(\begin{array}{c} h_{t}^{\prime}=\sigma\left(U c+W h_{t-1}^{\prime}+b_{hidden}\right) \\ y_{t}^{\prime}=\sigma\left(V h_{t}^{\prime}+b_{output}\right) \end{array}\)
第三种:
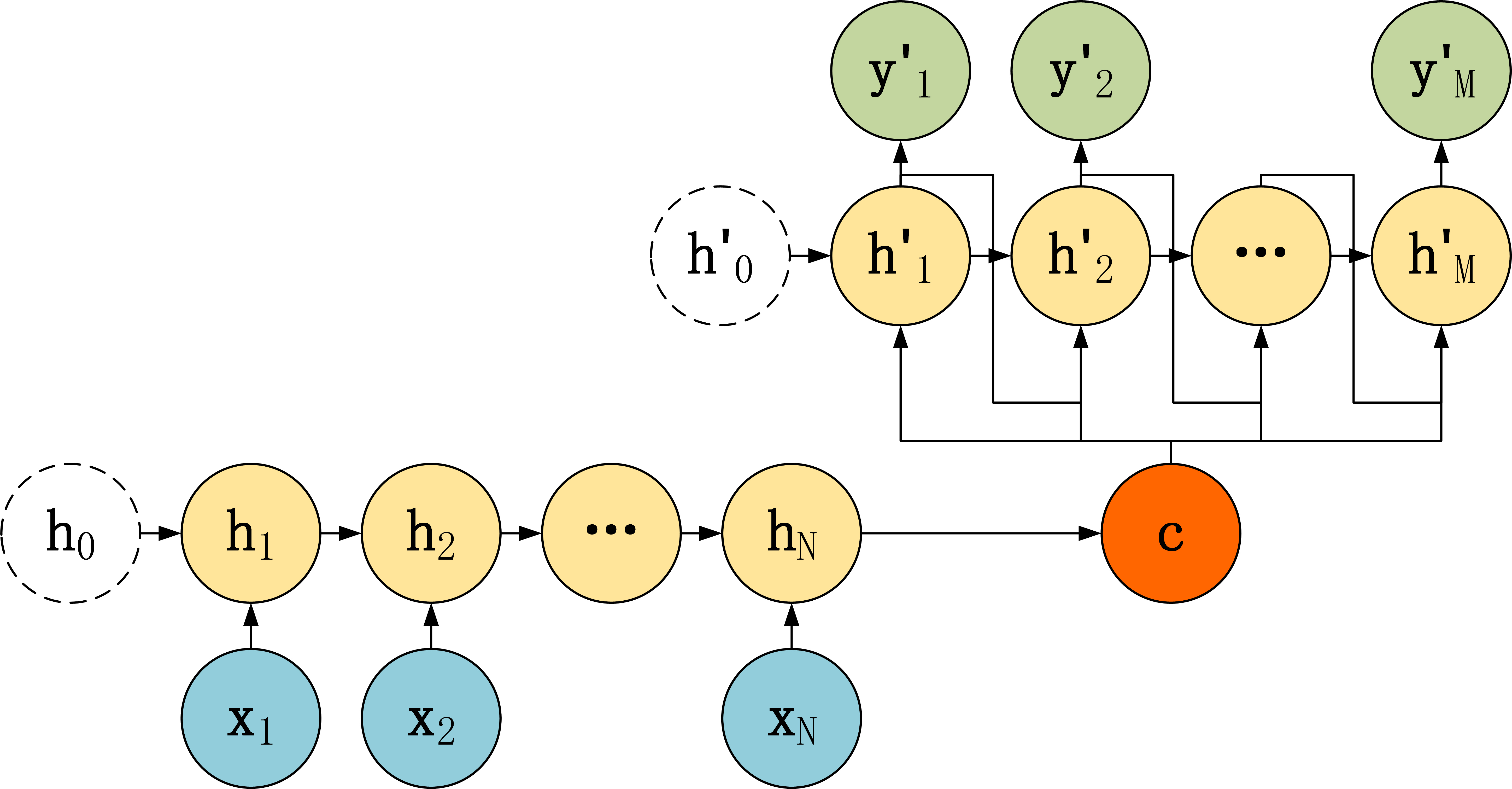
第三种 Decoder 结构和第二种类似,但是在输入的部分多了上一个神经元的输出 $y’$。即每一个神经元的输入包括:上一个神经元的隐藏层向量 $h’$,上一个神经元的输出 $y’$,当前的输入 $c$ (Encoder 编码的上下文向量)。对于第一个神经元的输入 $y’_0$,通常是句子其实标志位的 embedding 向量。第三种 Decoder 的隐藏层及输出计算公式: \(\begin{array}{c} h_{t}^{\prime}=\sigma\left(U c+W h_{t-1}^{\prime}+D y_{t-1}^{\prime}+b_{hidden}\right) \\ y_{t}^{\prime}=\sigma\left(V h_{t}^{\prime}+b_{output}\right) \end{array}\)
2.2. Attention
在 Seq2Seq 模型,Encoder 总是将源句子的所有信息编码到一个固定长度的上下文向量 $c$ 中,然后在 Decoder 解码的过程中向量$c$ 都是不变的。这存在着不少缺陷:
- 对于比较长的句子,很难用一个定长的向量 $c$ 完全表示其意义。
- RNN存在长序列梯度消失的问题(尽管这个问题在LSTM上有所缓和),只使用最后一个神经元得到的向量 $c$ 效果不理想。
- 向量 $c$静态不变,体现不了人类的真实阅读和理解文字时的注意力动态转变的特征,即人类在阅读或者翻译文章的时候,会把注意力放在当前的字词上。
Attention 即注意力机制,是一种将模型的注意力放在与当前输出最紧密的输入上面的一种机制。例如翻译 “I have a cat”,翻译到 “我” 时,要将注意力放在源句子的 “I” 上,翻译到 “猫” 时要将注意力放在源句子的 “cat” 上。
使用了 Attention 后,Decoder 的输入就不是固定的上下文向量$c$ 了,而是会根据当前翻译的信息,计算当前的 $c$。如下图所示:
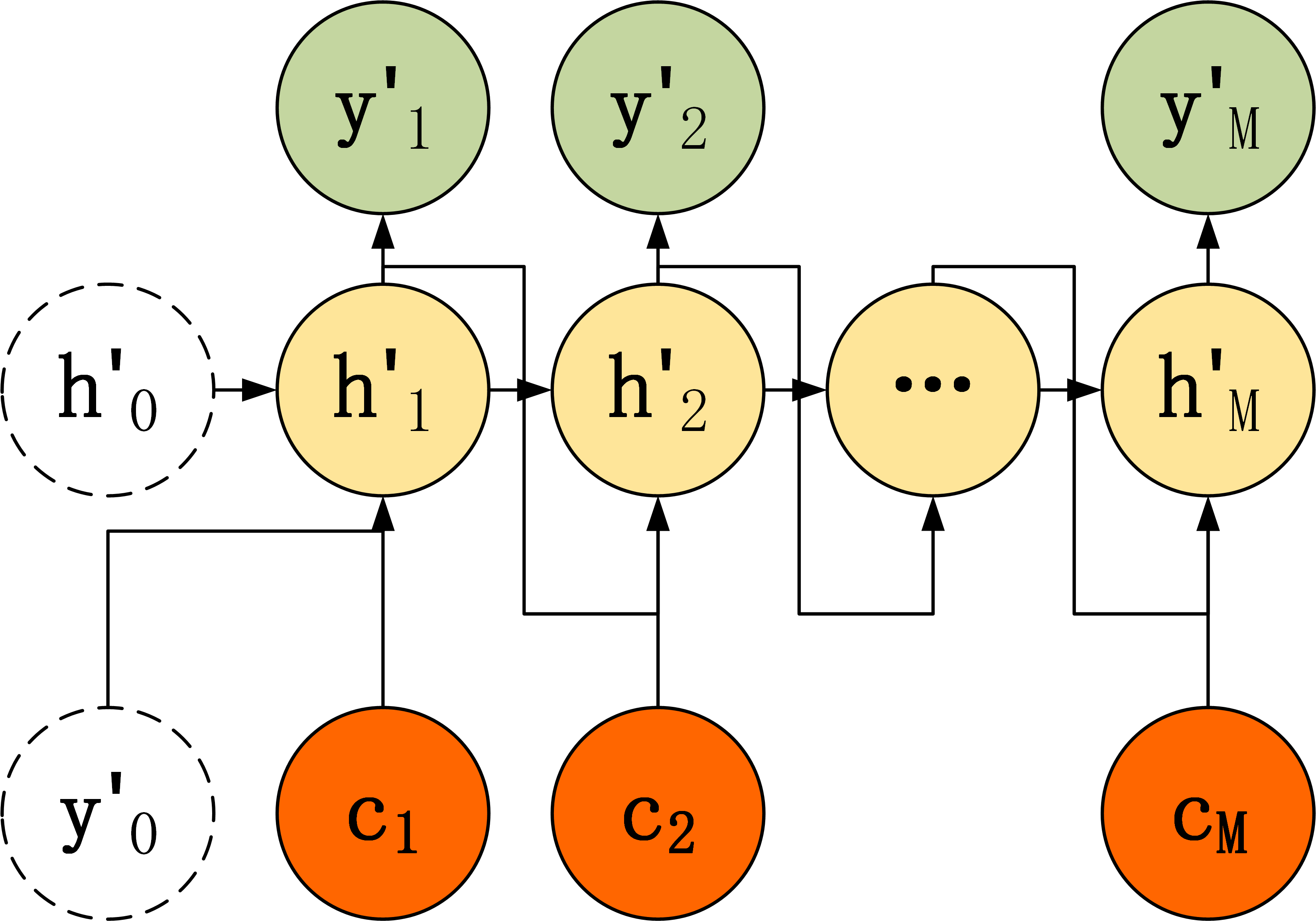
所以,Attention机制需要保留 Encoder 每一个神经元的隐藏层向量 $h$,然后 Decoder 的第 $t$ 个神经元要根据上一个神经元的隐藏层向量 $h’{t-1}$ 计算出当前状态与 Encoder 每一个神经元的相关性 $e_t$。(注意,$h’$和$h$的维度不一定相同)。$e_t$ 是一个 N 维的向量 (Encoder 神经元个数为 N),若 $e_t$的第 $i$ 维越大,则说明当前节点与 Encoder 第 $i $个神经元的相关性越大。假设函数$a$用于计算Decoder的$h’{t-1}$与Encoder的第$i$个神经元的相关性系数,那么,$e_t$可以表示为: \(e_{t}=\left[a\left(h_{t-1}^{\prime}, h_{1}\right), a\left(h_{t-1}^{\prime}, h_{2}\right), \ldots, a\left(h_{t-1}^{\prime}, h_{N}\right)\right]\)
函数$a$有很多种: \(\begin{array}{c} a\left(h_{t-1}^{\prime}, h_{i}\right)=h_{i}^{T} h_{t-1}^{\prime} \\ a\left(h_{t-1}^{\prime}, h_{i}\right)=h_{i}^{T} W_1 h_{t-1}^{\prime} \\ a\left(h_{t-1}^{\prime}, h_{i}\right)=\tanh \left(W_{1} h_{i}+W_{2} h_{t-1}^{\prime}\right) \end{array}\)
上面得到相关性向量 $e_t$ 后,需要进行归一化,使用 softmax 归一化。然后用归一化后的系数融合 Encoder 的多个隐藏层向量得到 Decoder 当前神经元的上下文向量 $c_t$: \(\begin{array}{c} \alpha_{t i} =\frac{\exp \left(e_{t i}\right)}{\sum_{j=1}^{N} \exp \left(e_{t j}\right)} \\ c_{t} =\sum_{i=1}^{N} \alpha_{t i} h_{i} \end{array}\) 当然了,也可以找到最大的$\alpha_{t i}$,把它置为1,其他为0。这样做相当于只考虑最相关的那个输入单元。
Reference
- https://www.jianshu.com/p/80436483b13b
- 秦曾昌 - 自然语言处理算法精讲 - Chapter 9