Pre-Training 的历史
最开始是在图像和视频领域兴起的。目前我们已经知道,对于层级的CNN结构来说,不同层级的神经元学习到了不同类型的图像特征,由底向上特征形成层级结构,如果我们手头是个人脸识别任务,训练好网络后,把每层神经元学习到的特征可视化肉眼看一看每层学到了啥特征,你会看到最底层的神经元学到的是线段等特征,图示的第二个隐层学到的是人脸五官的轮廓,第三层学到的是人脸的轮廓,通过三步形成了特征的层级结构,越是底层的特征越是所有不论什么领域的图像都会具备的比如边角线弧线等底层基础特征,越往上抽取出的特征越与手头任务相关。正因为此,所以预训练好的网络参数,尤其是底层的网络参数抽取出特征跟具体任务越无关,越具备任务的通用性,所以这是为何一般用底层预训练好的参数初始化新任务网络参数的原因。而高层特征跟任务关联较大,实际可以不用使用,或者采用Fine-tuning用新数据集合清洗掉高层无关的特征抽取器。
NNLM (2003年)
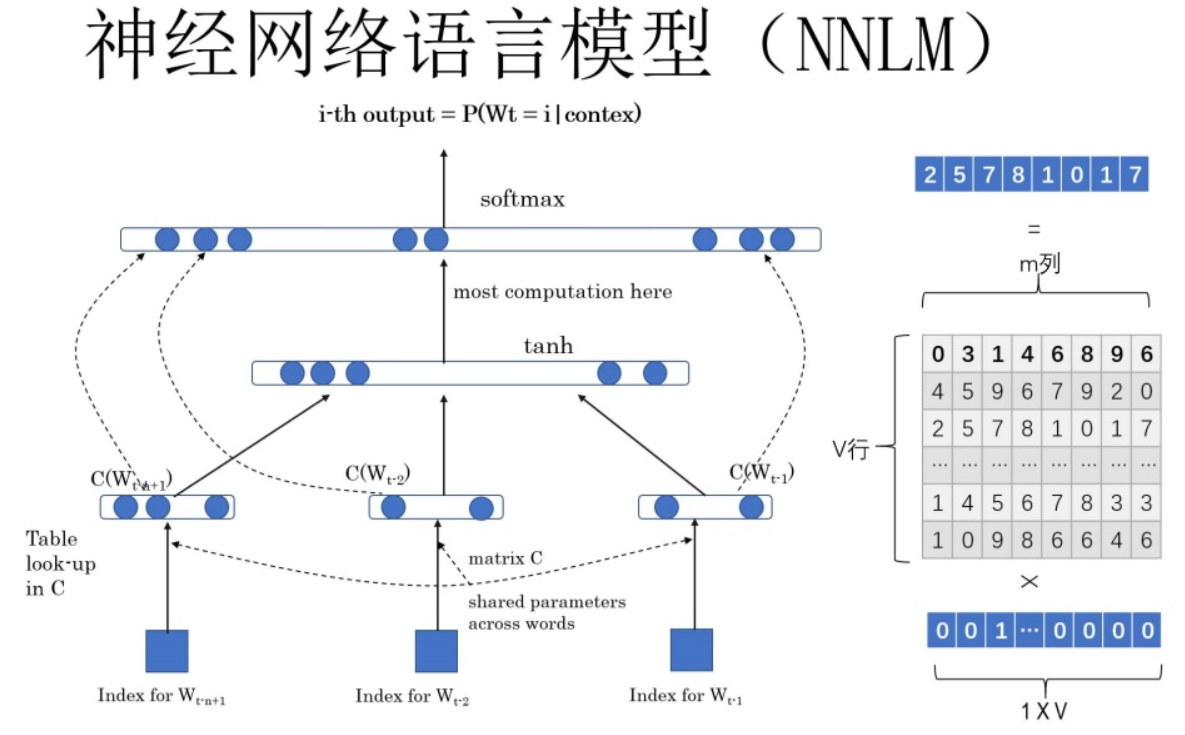
NNLM用Language Model来建模: \(P\left(W_{t} \mid W_{1}, W_{2}, \ldots W_{t-1}; \theta\right)\) 前面任意单词 $W_i$用Onehot编码(比如:0001000)作为原始单词输入,之后乘以矩阵Q后获得向量 $C(W_i)$,每个单词的 拼接 $C(W_i)$,上接隐层,然后接softmax去预测后面应该后续接哪个单词。这个 $C(W_i)$ 是什么?这其实就是单词对应的Word Embedding值,那个矩阵Q包含V行,V代表词典大小,每一行内容代表对应单词的Word embedding值。只不过Q的内容也是网络参数,需要学习获得,训练刚开始用随机值初始化矩阵Q,当这个网络训练好之后,矩阵Q的内容被正确赋值,每一行代表一个单词对应的Word embedding值。所以你看,通过这个网络学习语言模型任务,这个网络不仅自己能够根据上文预测后接单词是什么,同时获得一个副产品,就是那个矩阵Q,这就是单词的Word Embedding是被如何学会的。
Word2Vec
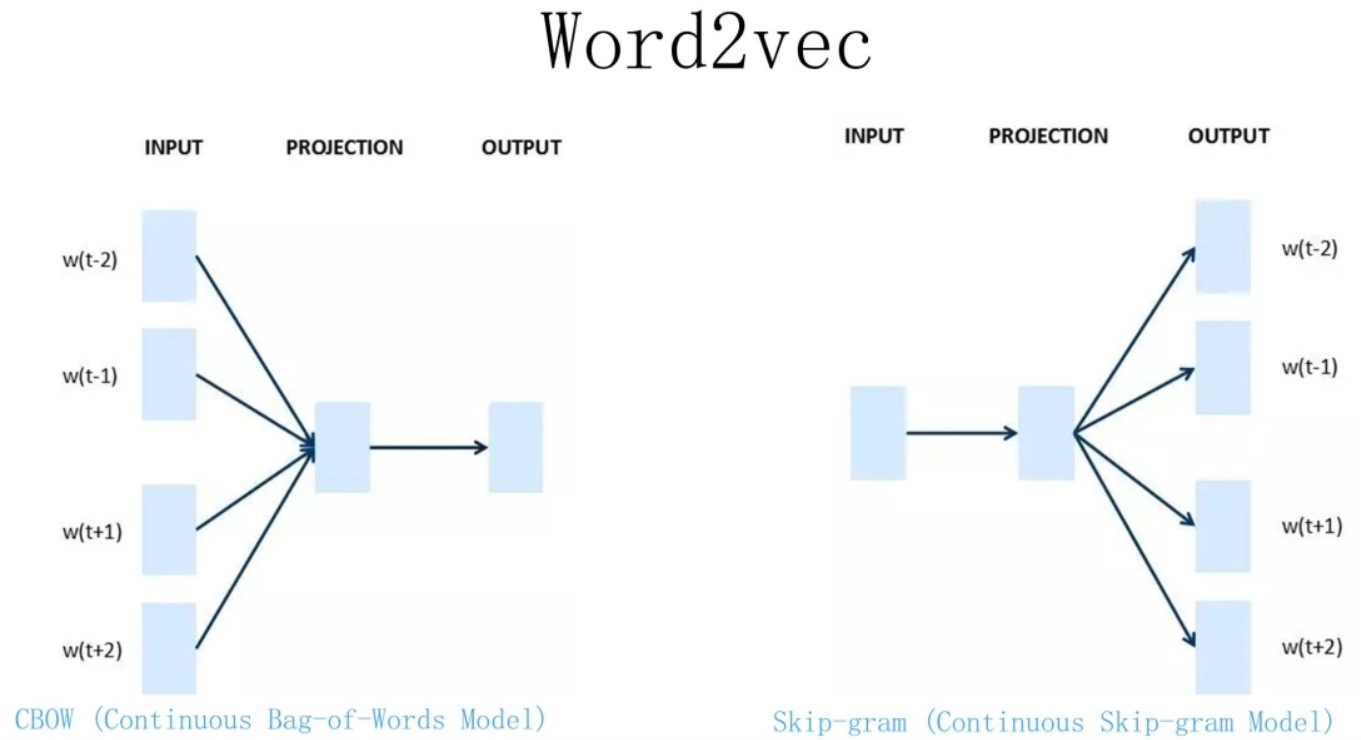
Word2Vec的网络结构其实和NNLM是基本类似的,只是这个图长得清晰度差了点,看上去不像,其实它们是亲兄弟。不过这里需要指出:尽管网络结构相近,而且也是做语言模型任务,但是其训练方法不太一样。Word2Vec有两种训练方法,一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。而你回头看看,NNLM是怎么训练的?是输入一个单词的上文,去预测这个单词。这是有显著差异的。为什么Word2Vec这么处理?原因很简单,因为Word2Vec和NNLM不一样,NNLM的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而word embedding只是无心插柳的一个副产品。但是Word2Vec目标不一样,它单纯就是要word embedding的,这是主产品,所以它完全可以随性地这么去训练网络。
我们的主题是预训练,那么问题是Word Embedding这种做法能算是预训练吗?这其实就是标准的预训练过程。要理解这一点要看看学会Word Embedding后下游任务是怎么用它的。下游NLP任务在使用Word Embedding的时候也类似图像有两种做法,一种是Frozen,就是Word Embedding那层网络参数固定不动;另外一种是Fine-Tuning,就是Word Embedding这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
Word Embedding存在什么问题?是多义词问题。我们知道,多义词是自然语言中经常出现的现象,也是语言灵活性和高效性的一种体现。多义词对Word Embedding来说有什么负面影响?如上图所示,比如多义词Bank,有两个常用含义,但是Word Embedding在对bank这个单词进行编码的时候,是区分不开这两个含义的,因为它们尽管上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过word2vec,都是预测相同的单词bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。所以word embedding无法区分多义词的不同语义,这就是它的一个比较严重的问题。
ELMO
ELMO提供了一种简洁优雅的多义词解决方案。一图明了。
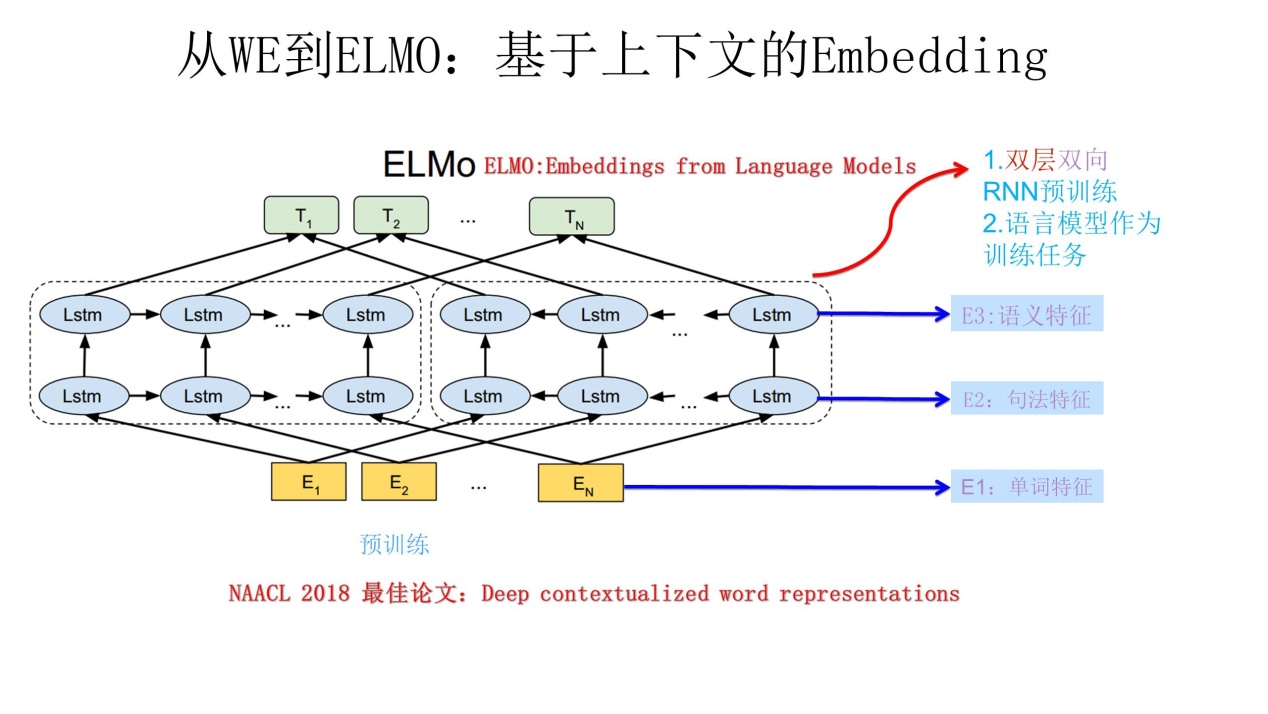
ELMO采用了典型的两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词$W_i$的上下文去正确预测单词$W_i$, $W_i$之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词$W_i$外的上文Cotext-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。这个网络结构其实在NLP中是很常用的。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子$S_{new}$,句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding (concat),这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
那么预训练好网络结构后,如何给下游任务使用呢?我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。至于为何这么做能够达到区分多义词的效果,你可以想一想,其实比较容易想明白原因。
ELMO有什么值得改进的缺点呢?首先,一个非常明显的缺点在特征抽取器选择方面,ELMO使用了LSTM而不是新贵Transformer,Transformer是谷歌在17年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响,很多研究已经证明了Transformer提取特征的能力是要远强于LSTM的。如果ELMO采取Transformer作为特征提取器,那么估计Bert的反响远不如现在的这种火爆场面。另外一点,ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱,但是,这只是一种从道理推断产生的怀疑,目前并没有具体实验说明这一点。
我们如果把ELMO这种预训练方法和图像领域的预训练方法对比,发现两者模式看上去还是有很大差异的。除了以ELMO为代表的这种基于特征融合的预训练方法外,NLP里还有一种典型做法,这种做法和图像领域的方式就是看上去一致的了,一般将这种方法称为“基于Fine-tuning的模式”,而GPT就是这一模式的典型开创者。
GPT
Motivation:
We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text
Challenges:
- optimization objectives is unclear
- no consensus on how to apply the learned representations on down-stream tasks.
Methods:
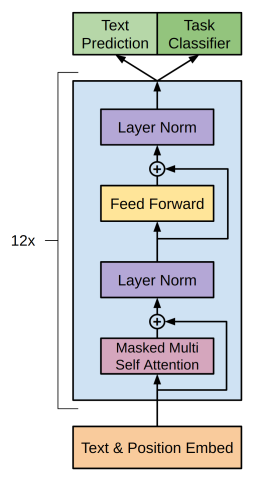
- 2-steps training, first unlabeled text, second domain-specific text, they don’t have to be in the same area. GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型. ELMO在做语言模型预训练的时候,预测单词同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
- process structured text input as a single contiguous sequence of tokens .
Performance:
- In four selected tasks - natural language inference, question answering, semantic similarity, and text classification - GPT outperforms those trained models that employ architectures specifically crafted for each task.
Model Details:
-
Unsupervised pre-training
-
input unsupervised corpus of tokens $\mathcal{U}=\left{u_{1}, \ldots, u_{n}\right}$,k is the size of content window
-
use language modeling objective $L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right)$, $\Theta$ denotes the neural network parameters.
-
multi-layer transformer decoder,注意encoder和decoder的不同之处。 \(\begin{aligned} h_{0} &=U W_{e}+W_{p} \\ h_{l} &=\text { transformer_block }\left(h_{l-1}\right) \forall i \in[1, n] \\ P(u) &=\operatorname{softmax}\left(h_{n} W_{e}^{T}\right) \end{aligned}\) $U=\left(u_{-k}, \ldots, u_{-1}\right)$ is the context vector of tokens, $n$ is the number of layers, $W_e$ is the token embedding matrix, and $W_p$ is the position embedding matrix.
-
-
Supervised fine-tuning
其实就down-stream task fine tuning。 假设数据为序列:$x^{1}, \ldots, x^{m}$,标签为:y。我们可以通过加一层线性output layer with parameters $W_y$来预测y:$P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right)$
那么目标函数就变成了: \(L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right)\) 作者其实发现了一个有趣的现象,如果在fine-tining的时候,加上一个language modeling作为auxiliary objective的话,模型性能会更好,收敛会更快。也就是说,现在我们的损失函数变成了($\lambda 是权重超参$): \(L_{3}(\mathcal{C})=L_{2}(\mathcal{C})+\lambda * L_{1}(\mathcal{C})\)
-
Task-specific input transformations
这部分讲的是对于不同的NLP任务,其实他们的输入是不同的,要如何transform他们的输入,以使得GPT可用于这些数据上。
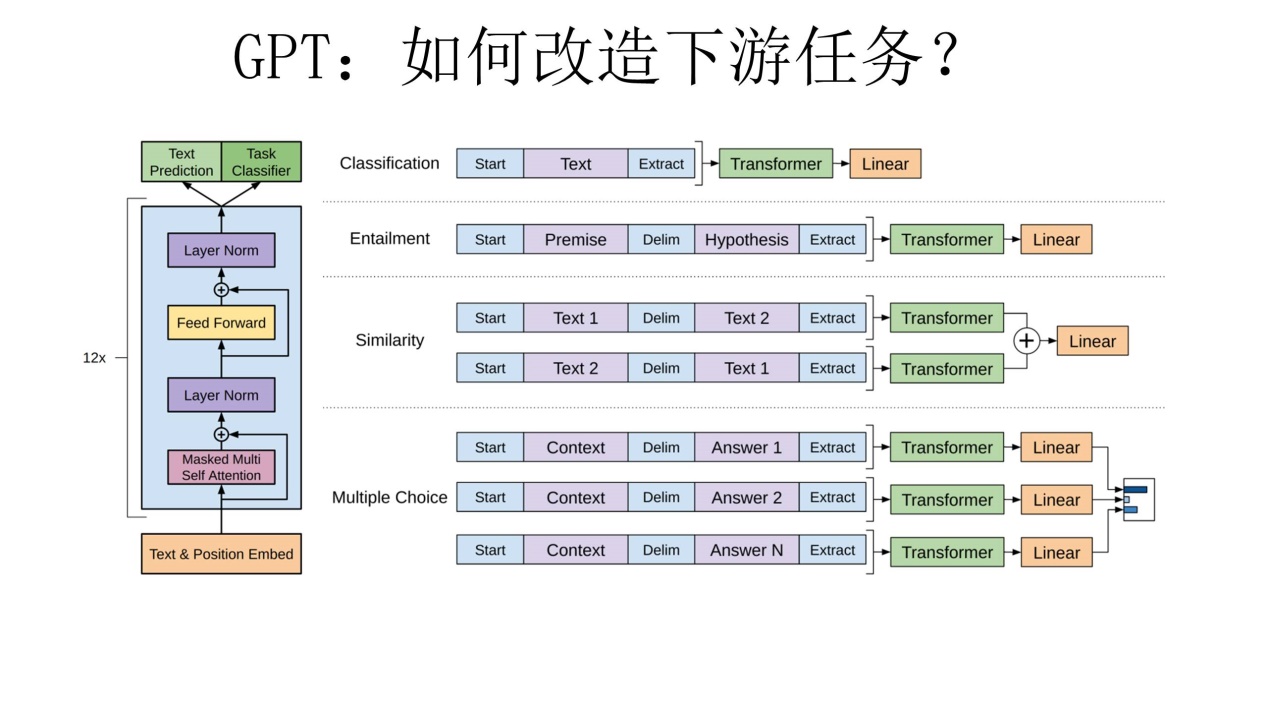
对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向GPT的网络结构看齐,把任务的网络结构改造成和GPT的网络结构是一样的(classification的方式)。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。就是这样。看到了么?这有没有让你想起最开始提到的图像领域如何做预训练的过程.
GPT有什么值得改进的地方呢?其实最主要的就是那个单向语言模型,如果改造成双向的语言模型任务估计也没有Bert太多事了。
GPT2
Motivation:
Current systems are better characterized as narrow experts . To build a more general systems that can perform many tasks.
Significance:
| 最早提出了a general system should model P(output | input, task) |
Methods:
Optimization objective: $p(x)=\prod_{i=1}^{n} p\left(s_{n} \mid s_{1}, \ldots, s_{n-1}\right)$
input samples:
- (translate to french, english text, french text)
- (answer the question, document, question, answer)
首先预训练阶段是单向无监督的语言模型,语言模型相当于在给序列的条件概率建模,GPT2思想通过大量无监督的语料训练语言模型,预训练语料大涵盖面广,提供模型跨任务能力,论文中提到Multi-task learners,这个如何理解,举两个简单的的例子,如预料是The translation of word Deep learning in Chinese is 深度学习,这样无监督语言模型就相当于把翻译模型的输入和输出学到了,又或者美国的总统是特朗普,这通过无监督语言模型又相当于问答系统
Model Details:
和GPT区别不大,主要改动如下:
- Layer norm放到了每个sub-block前(我还是有些没懂具体在哪里,之后看下源码)
- 残差层的参数初始化根据网络深度进行调节
- 扩大了字典、输入序列长度、batchsize
BERT
Motivations:
GPT 是单向的, 对于question answering这种需要上下文信息的场景其实并不好。
Key points:
- 两种方法应用pre-trained language representations: feature-based and fine tuning.
- feature based的方法用task-specific model to include the pre-trained representations as additional features,比如说ELMO
- fine-tuning的方法就像GPT那样了。
Methods:
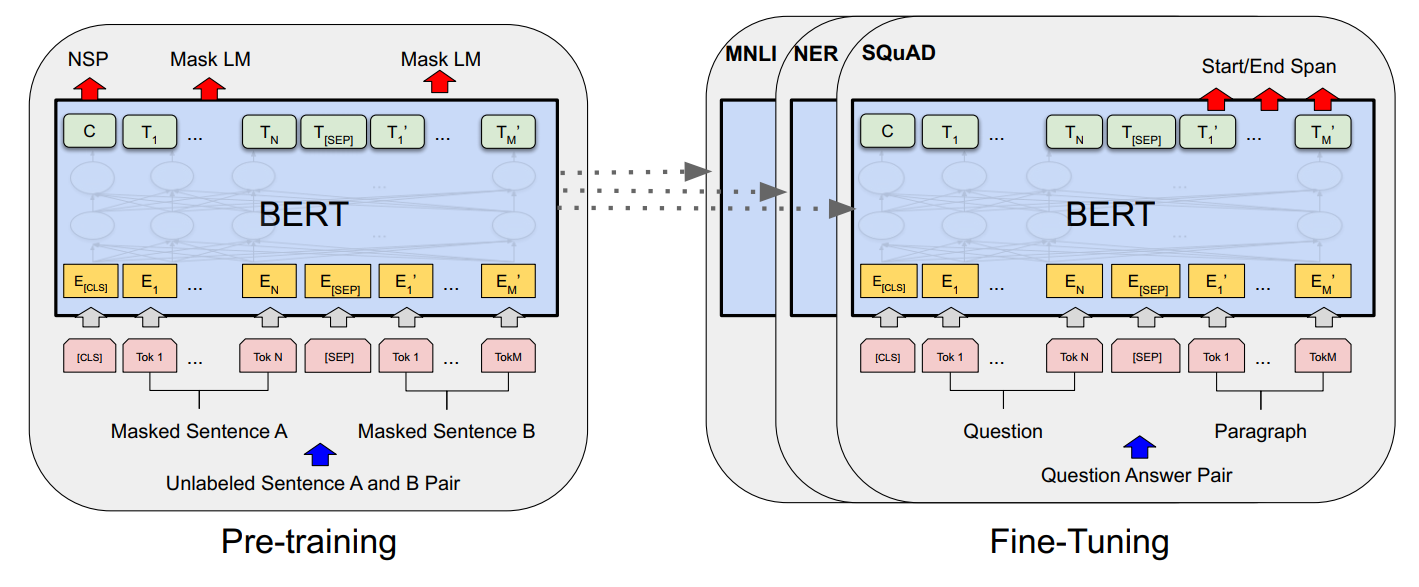
-
Input: a sequence, can be a single sentence or two sentences packed together. 比如说Question [SEP] Answer
-
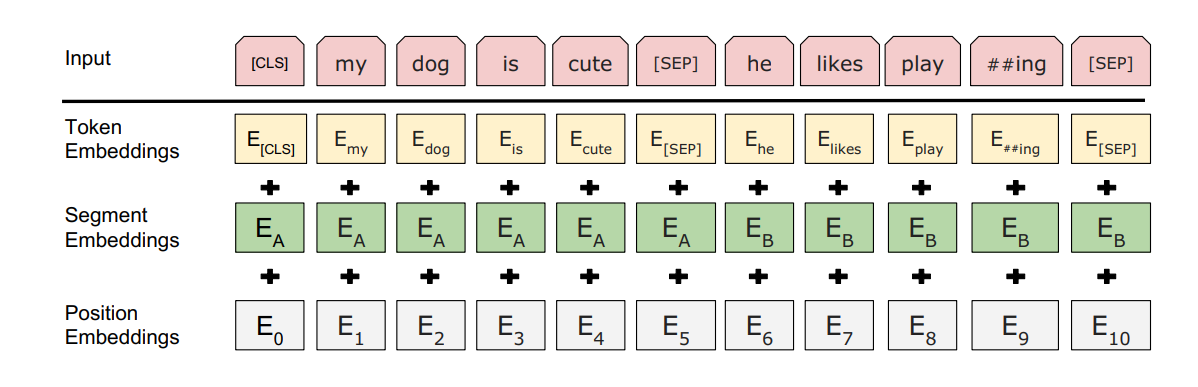
在input sequence 输入到bert之前,首先要把它进行token化。tokens化是使用一种叫做WordPiece token化的方法来完成的。这是一种数据驱动的token化方法,旨在实现词汇量和非词汇量之间的平衡。比如说,“strawberries”被分成“straw”和“berries”的方式。此外input的第一个位置会被插入一个[CLS] token,最后一个hidden state在这个对应位置上的输出C被当做sequence representation,但是C不是一个有意义的 sentence representation。
-
上图2中$E_A$和$E_B$表示segment embedding(学习来的),用来指示token属于哪一个句子
-
For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings.
-
训练方法
-
Masked LM:
simply mask some percentage of the input tokens at random, and then predict those masked tokens. 传统的LM task不支持information from both direction. 每个sequence会有15%的token会被[Mask] token所替代。但是呢,考虑到fine-tuning的场景不会出现[Mask] token,作者做了一个优化,对每一个被选中的token,80%的几率会被[Mask] token所替代,10%会被任意token所替代,10%不变。
-
Next Sentence Prediction:
这个任务是为了capture句子之间的关系,LM task很难做到这一点。上图1中的C就是用于NSP的,实验证明这个对QA和NLI类的任务非常有用。
-
-
训练数据,document-level corpus, 为了extract long contiguous sequences
-
各类task的Fine-tuning如下图,看完才知道,原来直接用embedding的方式其实是feature based downstream。Fine-tuning的时候,output layer是不一样的,这个需要注意。
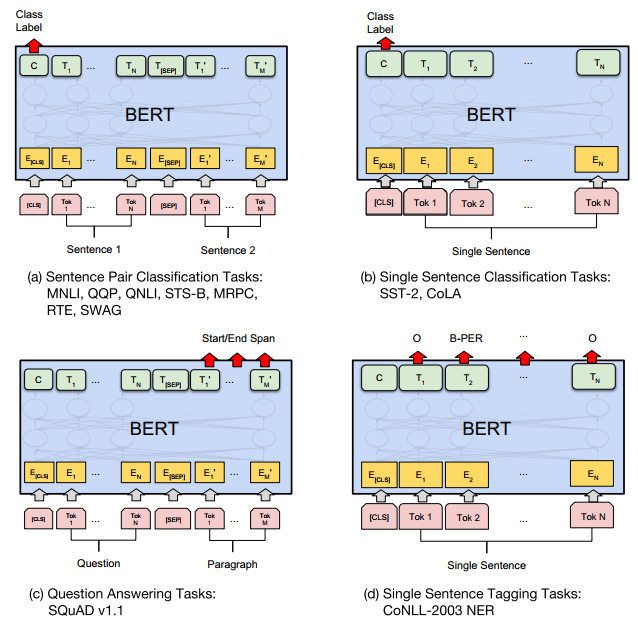
对于种类如此繁多而且各具特点的下游NLP任务,Bert如何改造输入输出部分使得大部分NLP任务都可以使用Bert预训练好的模型参数呢?上图给出示例,对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。从这里可以看出,上面列出的NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。尽管Bert论文没有提,但是稍微动动脑子就可以想到,其实对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。不论如何,从这里可以看出,NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
Reference
- https://zhuanlan.zhihu.com/p/49271699