Attention Models Specification
1. Seq2Seq + Attention
这里我们将会以Neural Machine Translation(NMT)做例子。
1.1. Seq2Seq
基本介绍就不说了,这里分析一下Seq2Seq的缺点:information bottleneck。因为Seq2Seq的input和output是变长的,而中间的memory(encoder hidden state)是定长的,所以如果输入序列很长的话,会导致靠前的信息被稀释,然后造成信息丢失。而且,后面的输入会得到更大的权重。
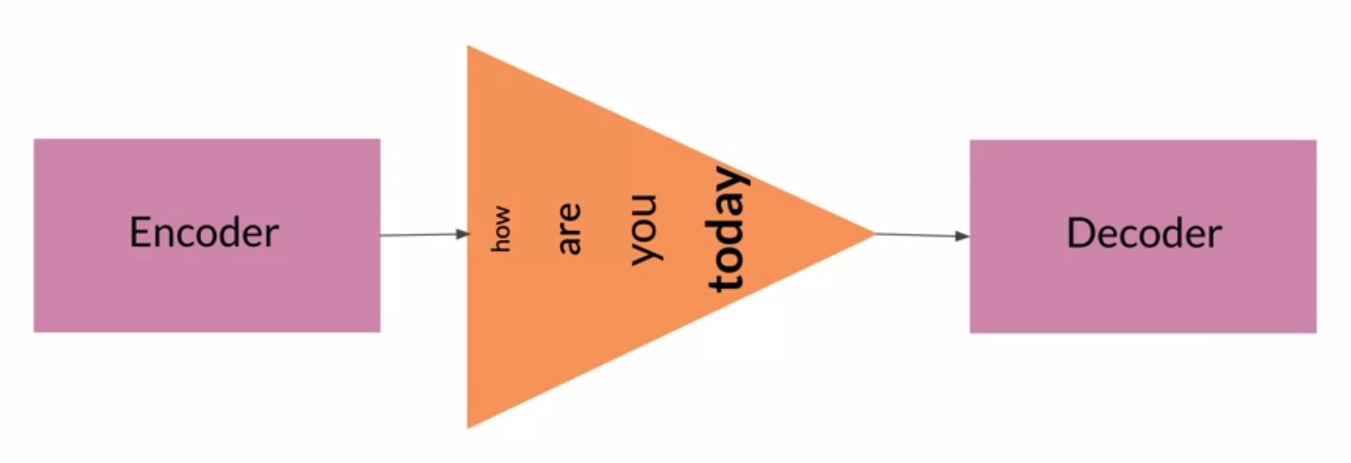
Seq2Seq在短序列数据上表现得很好,但是长序列就不太行了。
1.2. Alignment
Alignment Scores其实指的是Attention Weights.
1.3. Attention
Attention的3个重要components: key, value and query. Key 和 Value是成对的(很多时候key和value是一样的),维度也相同,他们来自于encoder hidden states. 如果用矩阵表示所有的key的话,行数就是输入序列长度,列数是向量维度。value 矩阵同理。Query来自decoder hidden states,query矩阵的行数可能和key矩阵不同,毕竟输入输出序列的长度不一定相同,但是向量维度是一样的。

Query和Key向量会用dot product的方式来计算他们的相似度。每一个Query和所有的Key的相似度都计算完之后,用softmax来计算一个分布,其实也就是Alignment Scores。然后每个value按位乘上自己对应的score再相加,得到输入decoder的memory。用矩阵表示为: \(\operatorname{softmax}\left(Q K^{T}\right) V\)
1.4. Setup for Machine Translation
- word2vec一下,vectorize每个token。
- 定义好句子的起止符号,和占位符(句子长度小于模型容纳长度时候用的)。
1.5. Training
Teacher Forcing:
在decoder中,它每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。Teacher Forcing能够使训练收敛更快更准确,不让错误积累。但是Teacher Forcing也有一个问题,就是在模型预测的时候,我们还是会用上一个state的输出作为下一个state的输入,所以这和在训练过程中有很大不同,模型就会变得脆弱。
NMT的训练过程和实现细节我们可以用下图概况。

- 0表示输入tokens,1表示目标tokens,Select([0,1,0,1])表示输入输出各复制一份。
- 从左边开始看起,一份输入,首先会embedding向量化,然后进入encoder的LSTM,每一个向量化的token进入一个LSTM cell去计算key和value(就是hidden state 输出,这里key和value是一样的)。
- 然后就是一份target,和上面那一份输入有点不同的是,这份target先会执行一个ShiftRight的操作。这个操作就是按位向右移动而已,比如说第二个target就是第三个输出位置的输入。显然,这一操作是为了实现teacher forcing。完事了之后,和上面无异了,embedding+LSTM,计算Query向量。
- 另一份输入token传上去到Fn层,我的理解是为了做masking,从输入里面知道哪些位置是需要mask的。Masking很简单,就是把输入序列里面的占位符的向量全都改成 -1 billion。这样做点积的结果非常非常小,softmax的概率也会为0。
- 另一份target token会传到输出那边做ground truth和prediction做比较。
- 然后呢,QKV就会做attention操作,residual的作用是,把query向量和对应的attention的结果相加。这个结果会做activation然后接着往下走。
- 然后到了图的右上角,这里我们会用select来drop掉mask向量,因为没啥用了。然后,activation会往下走,输入LSTM,然后每个cell的输出过dense层再做softmax求概率,而target token就会往右做ground truth的角色。
1.6. Evaluation
- BLEU score
- ROUGE score
2个都差不多,基于N元语法数数,需要的时候再了解。
1.7. Sampling and Decoding
-
Random Sampling,根据softmax的概率分布来抽样。这样太随机了。
-
Temperature in Sampling,Random Sampling的升级版,用temperature这个超参数来控制随机的程度,增大高概率的词的出现概率,减少低概率的词的出现概率。temperature取值范围0到1,越大越随机,越小越确定。
-
Greedy Decoding,每一步选择最大概率的词作为输出。对长序列不好。
-
Beam Search,每一步生成多个候选(这是一个超参数,beam size)的输出序列,并在此候选序列的基础上探索下一步的序列。其实就是条件概率。看看下面的例子:
假设字典为[a,b,c],beam size选择2,则:
- 在生成第1个词的时候,选择概率最大的2个词,(假设)那么当前序列就是a或b。
- 生成第2个词的时候,我们将当前序列a或b,分别与字典中的所有词进行组合,得到新的6个序列aa ab ac ba bb bc,然后从其中选择2个概率最高的,作为当前序列,(假设)即ab或bb。
- 不断重复这个过程,直到遇到结束符为止。最终输出2个概率最高的序列。
通过这种启发式搜索(heuristic search),可减小模型学习阶段performance与测试阶段performance的差异。
-
Minimum Bayes’ risk (MBR)
- 生成几个随机抽样decoding samples
- 两两比较similarity,比如说用ROUGE score。
- 选择有最高average similarity的sample
2. Transformers
这里我们将以Text Summarization做例子。
2.1. Transformers VS RNNs
RNN有一个很大的问题就识不能并行化,这会导致模型训练和预测都很耗时。序列越长,模型处理的时间越长。此外,RNN还有vanishing gradient的问题。还有一个问题之前在Seq2Seq模型也讲过,就是信息丢失的问题。
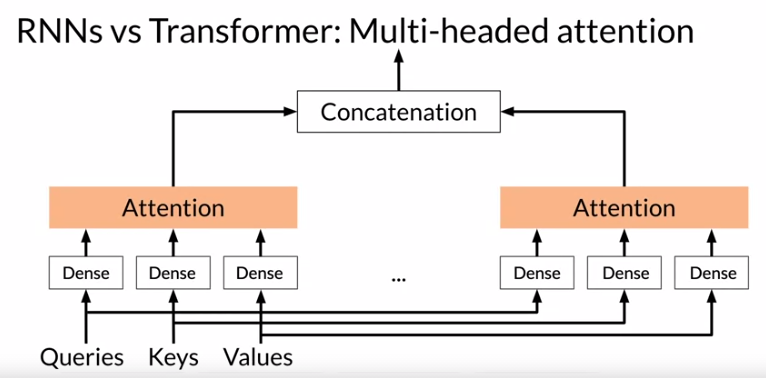
Transformer 最牛逼的地方是,用multi-head attention来替代RNN。那么Transformer怎么在没有RNN的情况下去解决输出序列的顺序问题呢?答案是positional encoding.
要了解什么是multi-head attention,我们先看看self-attention。简单来说,看下图,self-attention就是,对输入编码器的每个词向量,都创建 3 个向量,分别是:Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这些矩阵是我们要学习的参数。从实现的角度来看,其实每个矩阵就是一个dense层(全连接层)。
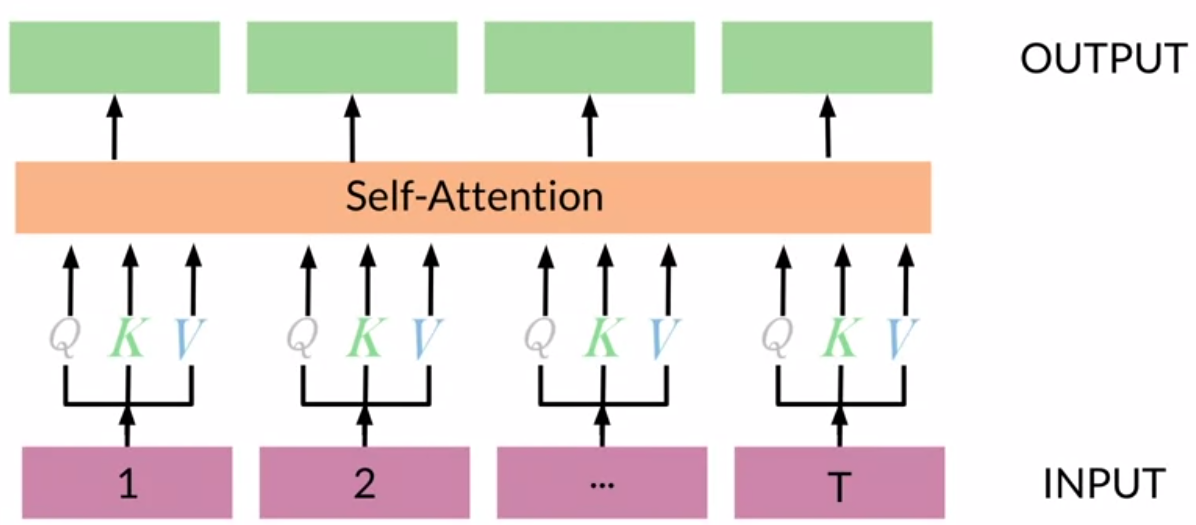
知道啥是self-attention之后,我们可以看看下图对multi-head attention有个大致的了解。然后再接下来的章节再细细道来。
2.2. Transformer Applications
2.3. Dot-Product Attention
一图解释所有:Q表示query向量集合,K表示key向量集合,V表示value向量集合。
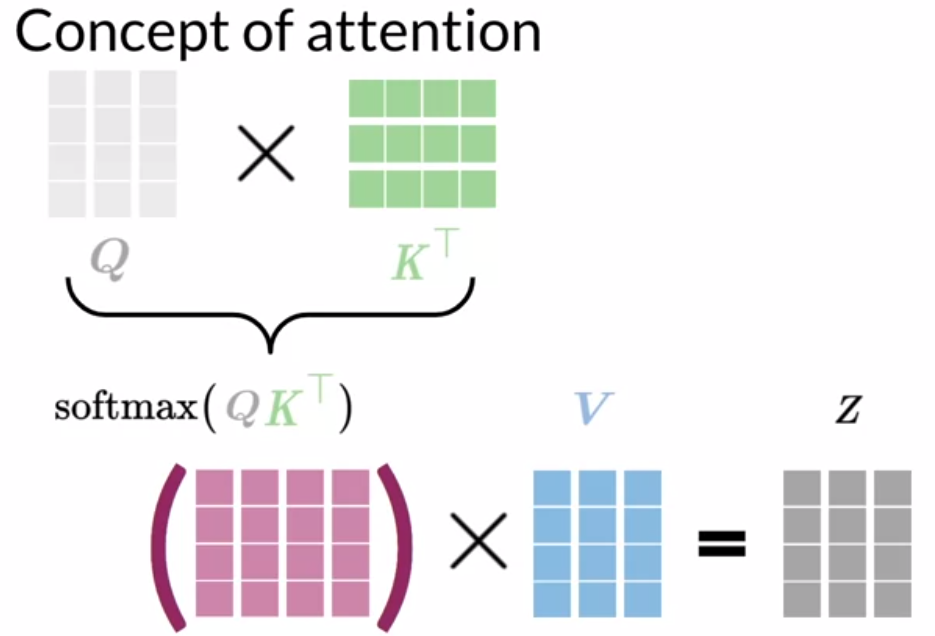
其中Q矩阵的行数是target sequence的长度,列数是每个向量的大小。K和V矩阵的行数是输入序列的长度,列数是向量大小,和query向量的大小相同。$\operatorname{softmax}\left(Q K^{\top}\right)$算出来的矩阵,我们一行行看,其实就是每个query的对应的输入序列的每个词的attention scores的分布。然后再乘以V矩阵,我们得到的矩阵Z其实就是,每一个query对应的输入序列的weighted average value向量。也就是,输入序列的每个词的value向量的所有维度乘以对应的attention score,然后相加。
2.4. Causal Attention
三种attention的方式:
- Encoder-Decoder attention: one sentence (decoder) looks at another one (encoder)
- Causal (self) attention: In one sentence, words look at previous words, 主要用在句子生成的场景,很简单的道理,句子生成的时候是一个个生成的,将来的词都没生成,所以不能pay attention to。
- Bi-directional self attention: In one sentence, words look at both previous and future words, Bert和T5用的是这个
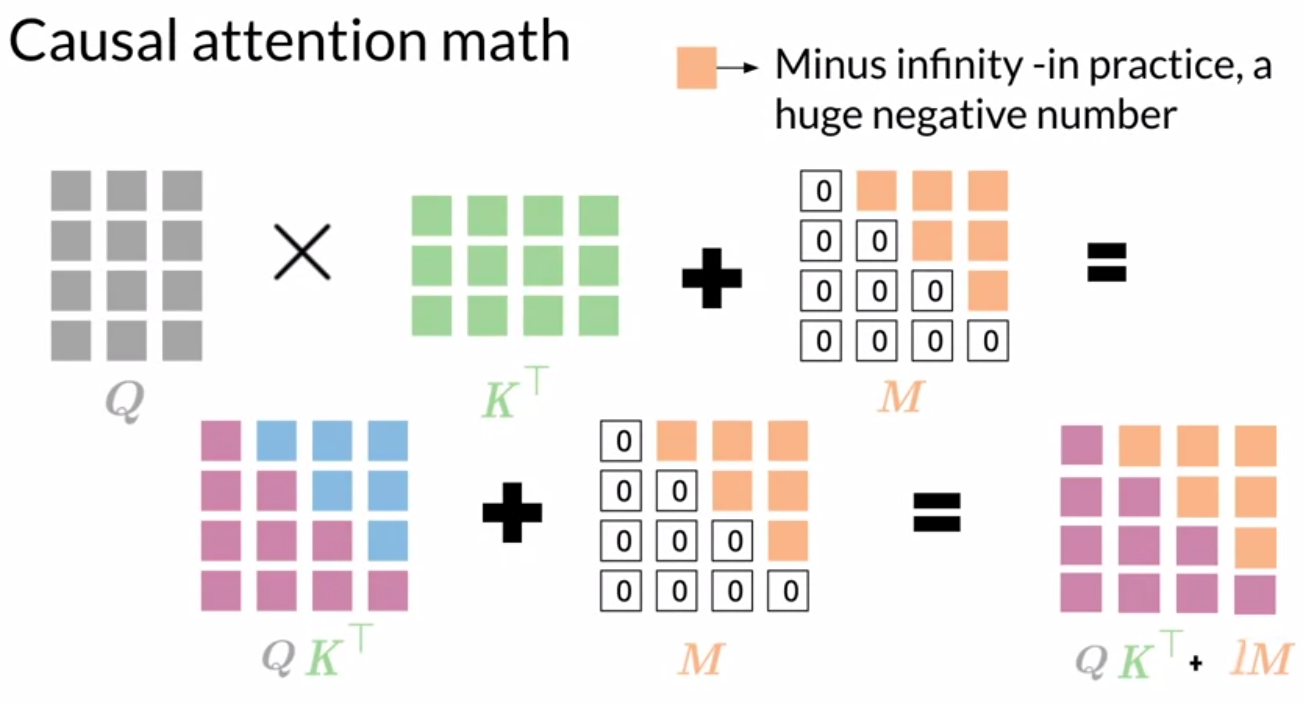
关于Causal attention的实现其实也是十分清楚明确,看下图,就是在softmax之前,加一个M矩阵就可以了。
2.5. Multi-head Attention
2.6. Transformer Decoder
2.7. Transformer Summarizer
其他
这一part主要是后来看了一些资料加深对模型细节的了解,暂时只做描述,不做归类
-
dense矩阵的共享理解
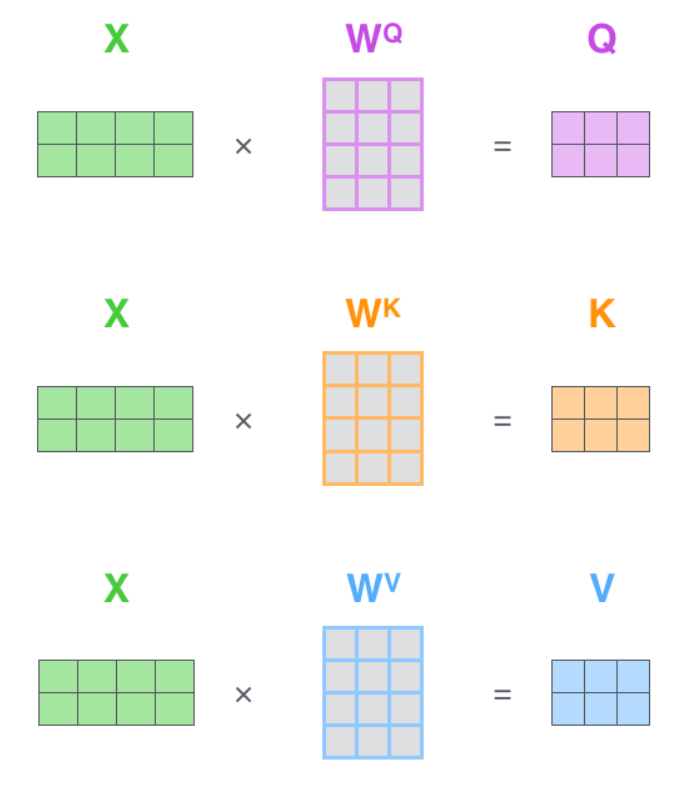
其实从下图可以看得出来,Q, K, V的参数矩阵应该是所有输入词向量共享的。
-
关于self-attention,其实就是输入词向量矩阵copy三份(有时两份,如果K,V一样的话),分别过dense layer(等同于乘以上面的系数矩阵),求得QKV。然后做attention操作,$\operatorname{softmax}\left(Q K^{T}\right) V$,记得attention层的输出就是加权的V。
-
multi-head attention本质上是self-attention,不同的是输入会进行多次self-attention,然后就得到多个加权的V了吗,然后把它们都concat起来,我们把结果叫Z吧,Z的维度最后会和X一样。
-
输入序列其实可以直接表示为矩阵的理解,这个和LSTM-based的encoder不一样了吧,在transformer里面,输入序列其实就是用矩阵表示就好了,如上图X。
-
encoder和decoder的区别
先看原图:
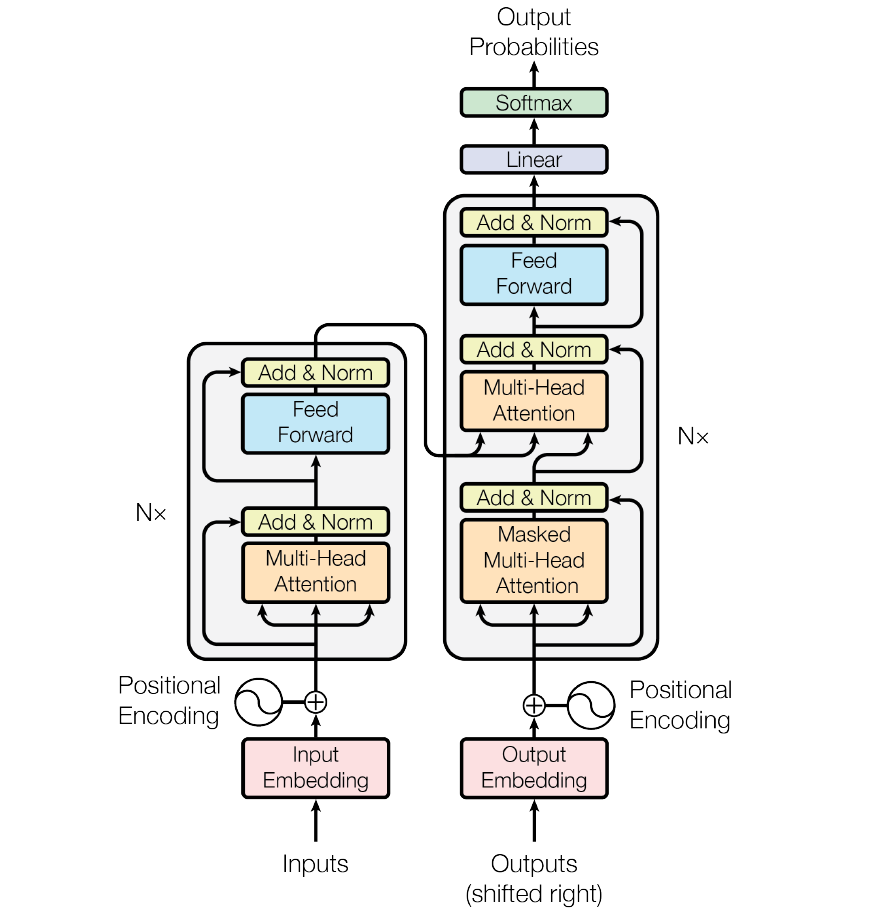
再看细节图:
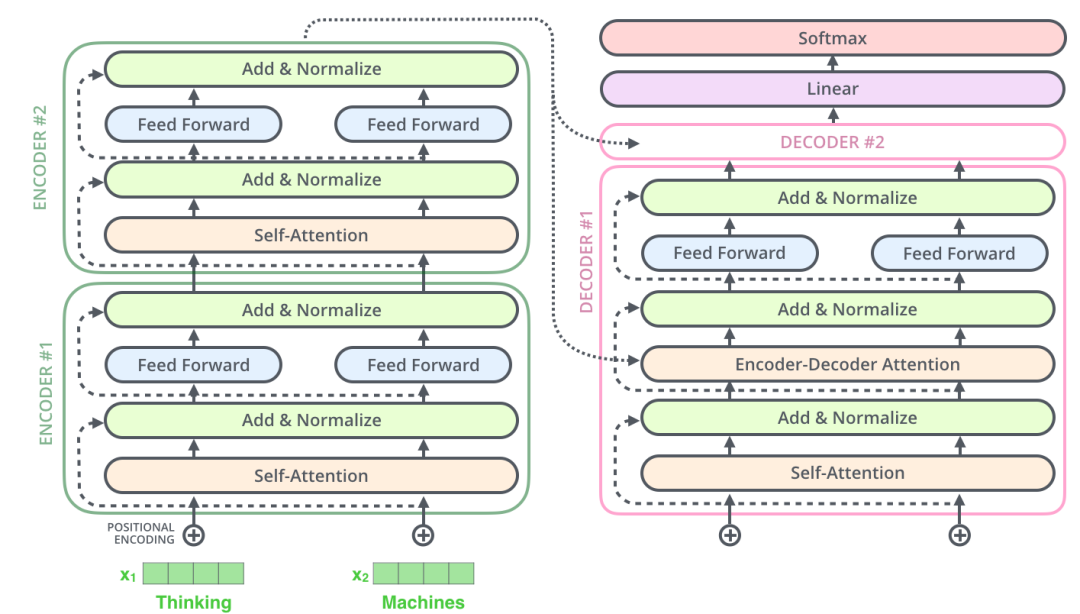
区别注意是2方面:
-
Decoder的第一层是Masked Multi-head Attention,也就是causal attention,注意这一层也是multi-head,所以最后输出的话,维度和输入向量是一样的
-
然后呢上面的输出回进入到Decoder独有的一层,Encoder-Decoder attention,这个就是之前介绍的3种attention方式之一(Q来自decoder,KV来自encoder)。这个KV来自encoder是为啥呢,encoder这边,输入经过了multi-head attention之后又回到了原本词向量的大小,我的理解是呢,这时候,这个attention之后的词向量回再经过fead -forward(KV当成相同就好了),生成KV向量传递到decoder。而来自decoder的Masked Multi-head Attention的向量呢,就直接作为Q向量。这些QKV的向量都是和输入向量维度是一致的我觉得。
-
-
关于decoder的输入,就是traget shift right。其实把它理解我一个个输入是最好理解的,但是呢,我们采用的是teacher forcing,其实等价于直接矩阵式全部输入。在测试的时候就不行了,要一个个来。
-
decoder序列输出的理解,这个就是也没啥说的,训练的时候就是矩阵进矩阵出。测试的时候就一个个进一个个出,直到EOS。虽然看起来两种形式,但是模型参数格式是通用的,想想就知道了。
-
gpt - only decoder的结构理解。其实不用纠结于decoder的这个说法,感觉这么说也只是因为gpt用了masked multi self attention而已。输入的是大段文字序列,然后定义了一个window content size k,用前k个词去预测当前词。所以self attention只在前k个词那里做,屏蔽了其他位置的。细想一下,其实和典型的transformer的decoder输入和mask-sefl-attention的处理是一样的。
可以想想gpt为啥不用encoder-decoder的结构呢,我觉得是他们建模的任务不同,transformer原本是对翻译建模,而gpt是对LM建模,所以有decoder就够了。GPT下游的话应该只能做分类的任务。
-
bert - only encoder的结构理解。bert的话,如果对Masked LM建模,encoder那边输入应该是masked 的sequence。用encoder已经可以表达了。如果对NSP建模,encoder也一样可以。反正,目前看来,只要不涉及到masked self-attention, 其实都可以用encoder来表达。bert的输出应该也是要维护整个序列的,不是只输出选中的masked或者replaced的词。只有这样,bert设计的那个mask和replace的策略才有意义,能够维护每个输出位置的向量。
-
对pre-training的一些理解:之前理解得有些狭隘其实,以为所有都是生成了word embedding(word2vec, elmo仍然是),现在才知道向GPT,bert原来是train一个较general的模型,然后在下游各种任务中fine tunning。当然啦,把gpt和bert输出当成embedding也是可以的,然后另外加功能层去实现自己想要的功能。比如说Bert+LSTM+CRF。
-
positional embedding的理解。其实现在想来,所有pre-train的模型,以及transformer,他们的输入,其实已经是word embedding了,当然啦,经过这些模型的加工,可以成为新的embedding。然后,positional embedding呢,是在模型输入之前,就已经加上embedding那里了,为了让位置的信息能够被考虑。包括BERT的segment embedding,其实是同样的道理。反正,这些位置信息,顺序信息,总归是一个信息,肯定有啥用,所以先考虑进去就对了,丢了反正很可惜。综上,positional embedding并不是像我之前想的那样,决定输出的顺序。
Reference
- deeplearning.ai 的专题课程 Natural Language Processing Specialization 第四课。
- 图解Transformer:https://mp.weixin.qq.com/s/oGf01yf1eG7zvc1oMPEl0g